

Using an S3 data source in QuickSight can often be challenging due to the unstructured nature of the data and the possibility of varying file formats. However, these limitations largely depend on the specific requirements, data formats, and the volume of data. Below are a few approaches to connecting S3 data sources in QuickSight.
Connecting S3 data source directly from Quicksight
Connecting directly to S3 buckets and files from QuickSight requires a manifest file, which can either be provided as a URL or uploaded locally. The S3 manifest file is in JSON format and includes details such as the file location, URI, prefix, and global upload settings for the S3 files. QuickSight processes the JSON manifest file and imports all associated files into SPICE for further analysis. If the file mentioned in the manifest or uploaded file is not found, QuickSight terminates the process and returns an error.
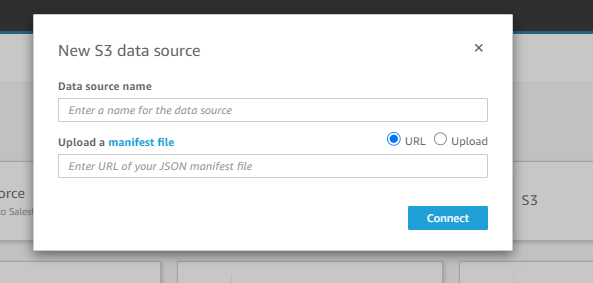

Manifest File Format:
The following JSON code is the format for the manifest files while performing the S3 imports in Quicksight.
{
"fileLocations": [
{
"URIs": [
"uri1",
"uri2",
"uri3"
]
},
{
"URIPrefixes": [
"prefix1",
"prefix2",
"prefix3"
]
}
],
"globalUploadSettings": {
"format": "CSV",
"delimiter": ",",
"textqualifier": "'",
"containsHeader": "true"
}
}
fileLocations: Use the fileLocations element to specify the locations of the import files. You can utilize either or both of them URIs and URIPrefixes arrays. At least one value must be provided in either of these arrays.
- URIs: URIs are the list of file locations of the files to be imported into Quicksight. URI format example: https://s3.amazonaws.com/<bucket name>/<file name>.
- URI prefixes:
URIPrefixesare the prefixes of S3 buckets and folders. All files within the respective bucket or folder are imported into QuickSight. Amazon QuickSight also supports recursively retrieving files from subfolders. URIPrefixes example: https://s3.amazonaws.com/<bucket name>.
Globalupdatesetting: You can provide field delimiters and other import options for the Amazon S3 files using this element. If this element is not supplied, Amazon QuickSight will use the default values for the fields in this section.
- Format: Set the file formats that will be imported. CSV, TSV, CLF, ELF, and JSON are all acceptable formats. CSV is the default selection.
- Delimiter: Set the delimiter for the file field. The format field’s file type specification must be mapped to this. Commas (,) and tabs (t) are acceptable formats for .csv and .tsv files, respectively. The comma is the default value (,).
textqualifier: The file text qualifier must be specified. Single quotes (‘) and double quotes are acceptable formats ” (\”). JSON requires the leading backslash as an escape character before a double quotation.
Containsheader: Indicate whether a header row exists in the file. True or false are acceptable formats. True is the default setting.
Another limitation with this approach is that certain file formats are not supported for instance Avro, parquet, and orc.
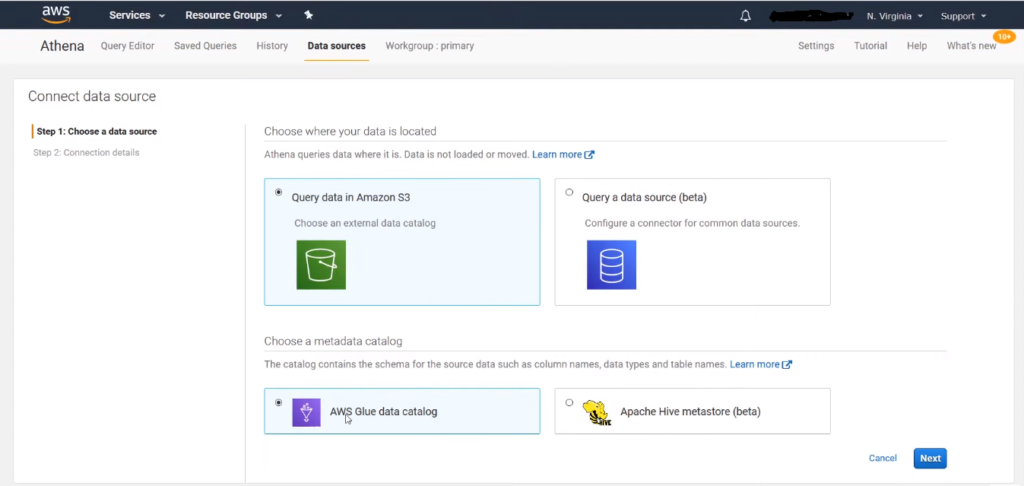
Connecting S3 data source through AWS Glue and AWS Athena:
In this scenario, AWS Glue works in tandem with Athena to create a data catalog from the data received from the S3 bucket. The data catalog contains the schema for the source data, including column names, data types, and source names.

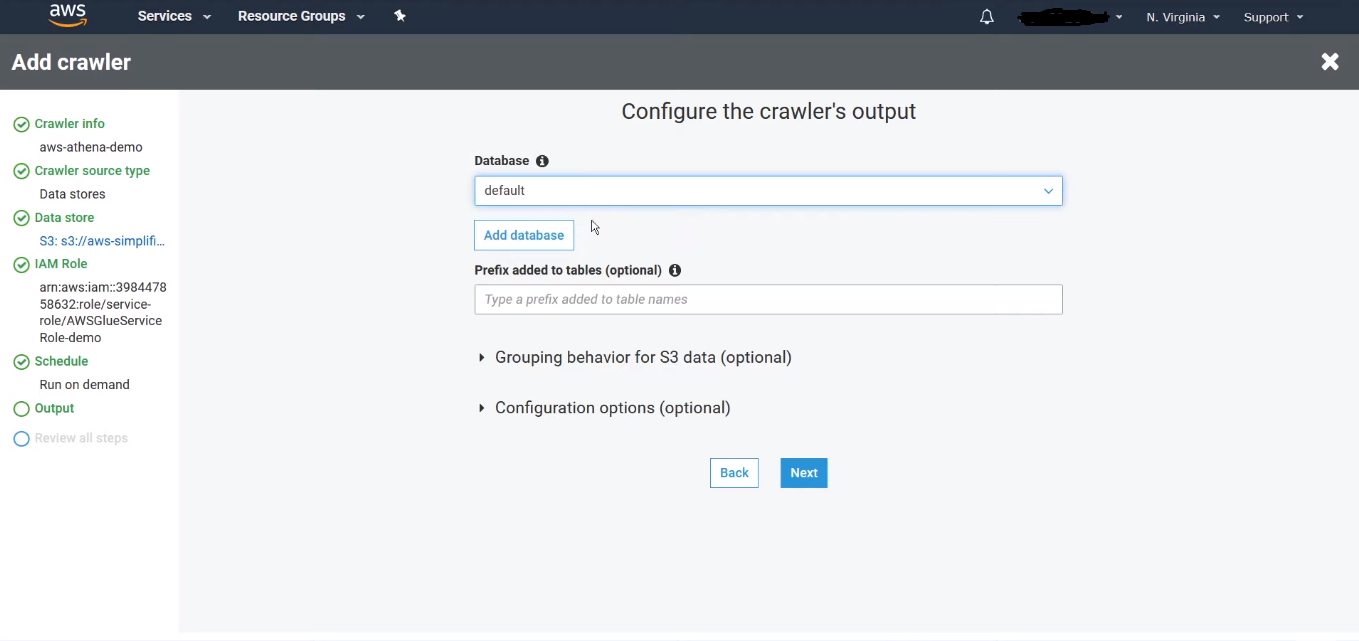
AWS Glue sets up a crawler in its environment to regularly crawl data from the data source either on a schedule or on demand. The Glue classifier identifies the data format and assigns the appropriate data type to all the columns, which are mutable. The metadata is then stored in the Glue catalog.

This schema information also appears in Athena, allowing us to perform custom queries on the data physically stored in the S3 bucket. By connecting the Athena data source to QuickSight, we can query the data present in S3, regardless of its format. This approach eliminates the need to import the entire S3 data into SPICE. Instead, a direct query is applied to the S3 data via the Athena catalog, retrieving the preferred columns with the required data transformations applied.
Connecting S3 data source through AWS Athena
In this approach, based on the information in the S3 data source, tables and schema information are manually added in Athena. Since AWS Glue is not involved to automatically identify the metadata of S3 files, the cost of running Glue is eliminated. Moreover, unlike AWS Glue, the configurations are performed manually, but there are no limitations to what can be configured, providing more flexibility compared to Glue’s automatic processes.
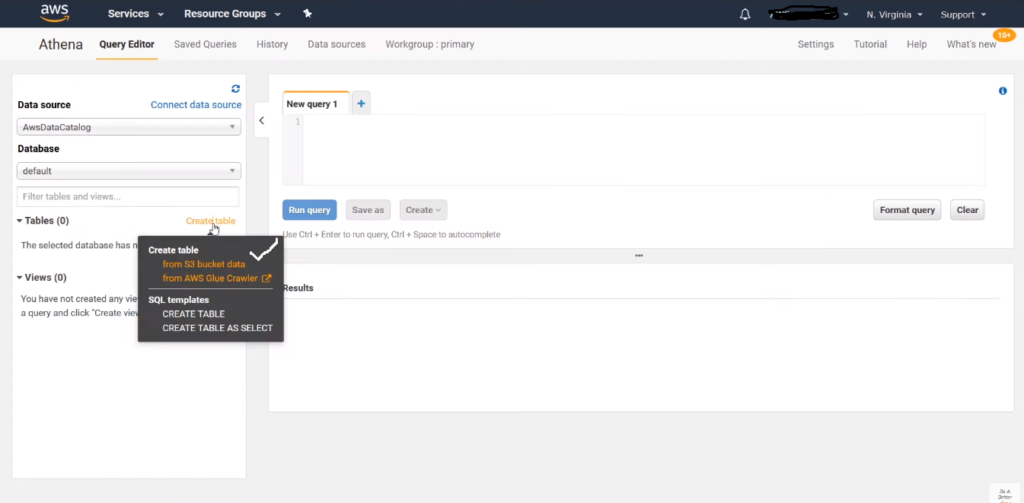

The columns can be added either individually or in bulk after creating the database and tables in Athena. Similarly, the data format is manually selected to match the format present in the S3 data source.
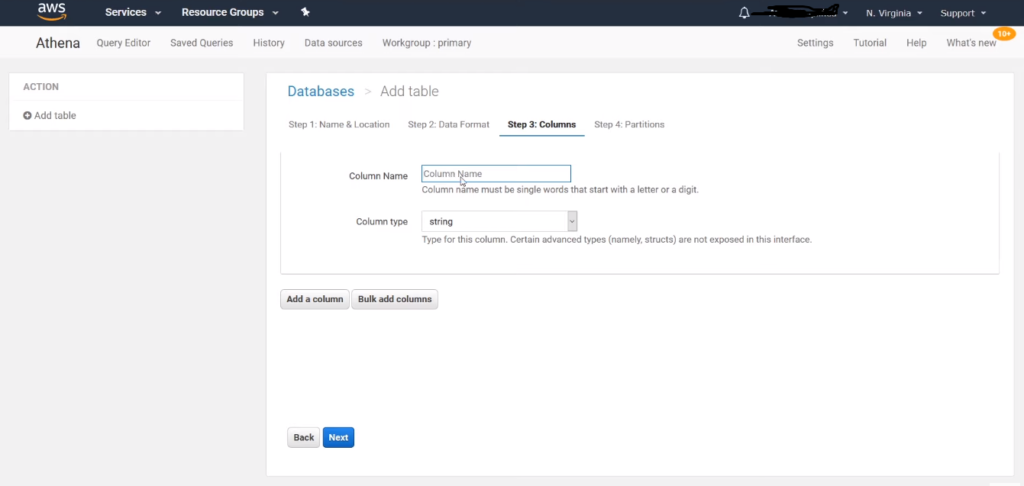

In addition, partitioning is supported in Athena for efficient querying of data. Similar to the previous approach, both direct query and SPICE modes are enabled for the Athena data source in QuickSight.
In conclusion, a direct connection to the S3 data source always imports the data into SPICE, and direct query is not applicable. When connecting to Athena in QuickSight, you have the option to use either Direct Query or import the data into SPICE. You also gain the ability to use Custom SQL with Athena, allowing for data transformations. Lastly, Athena supports querying Parquet, Avro, and other formats, whereas Parquet files cannot be imported using the direct S3 connection.


Learning is what makes me excited. I have a handful of experience as a data and BI analyst with broad skills across various tools. I am also a person who take up challenges and who work for it untill it get resolved. I have learnt to be spontaneous and precision in problem solving because of the experience over the years.