
AWS skills for data engineers have become essential nowadays to land a high-paying job with top players such as TCS, amazon, google, IBM, Infosys, and so on. Moreover, in the case of data engineering positions, companies expect not just one specific skill or service but instead 3 to 4 services with a full fledge knowledge and working experiences along with it.
Because implementing real-time data pipelines and data processing technologies across the growing volume of data in organizations involves enormous work and requires more skills. Following are some of the top 5 most sought-after skills among data engineers.
1. AWS Glue
AWS glue is an ETL service that extracts data from S3 Buckets or other data sources to perform transformation and store the results in the destination source (S3, Redshift, RDS) for analytics, Machine Learning, and software applications.
It allows integration from multiple data sources for processing and scales automatically based on the volume of data as and when required, therefore, human intervention to expand the resources in case of higher utility is redundant.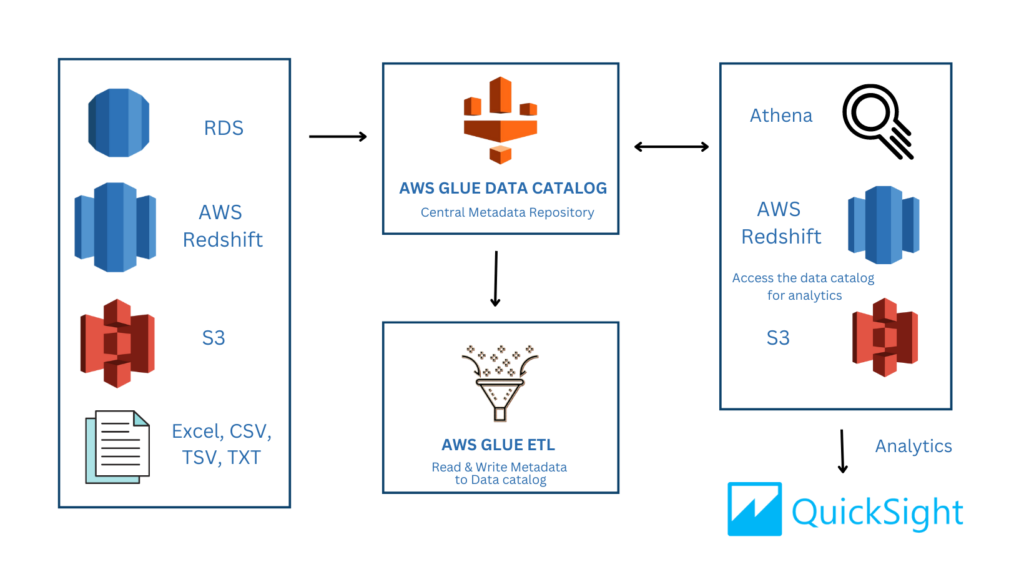 It identifies the data across multiple data sources quickly regardless of the different data formats and makes it immediately available for querying in Athena. Data engineers can interactively examine and prepare data using their preferred integrated development environment (IDE) or notebook by using AWS Glue interactive sessions.
It identifies the data across multiple data sources quickly regardless of the different data formats and makes it immediately available for querying in Athena. Data engineers can interactively examine and prepare data using their preferred integrated development environment (IDE) or notebook by using AWS Glue interactive sessions.
2. AWS EMR
AWS EMR is a solution to run Hadoop and spark jobs on clusters in AWS, it is a serverless platform that doesn’t require maintaining clusters and machines as everything is automatically handled in the backend. Without needing to adjust, maintain, optimize, protect, or manage clusters, Amazon EMR enables data engineers and analysts to run applications created using open source big data frameworks like Apache Spark, Hive, or Presto quickly and affordably.
It can collect data from multiple sources, process it at scale, and make it accessible to users and applications. Also, allows the creation of long-running, highly available, fault-tolerant streaming data pipelines via real-time event analysis from streaming data sources.
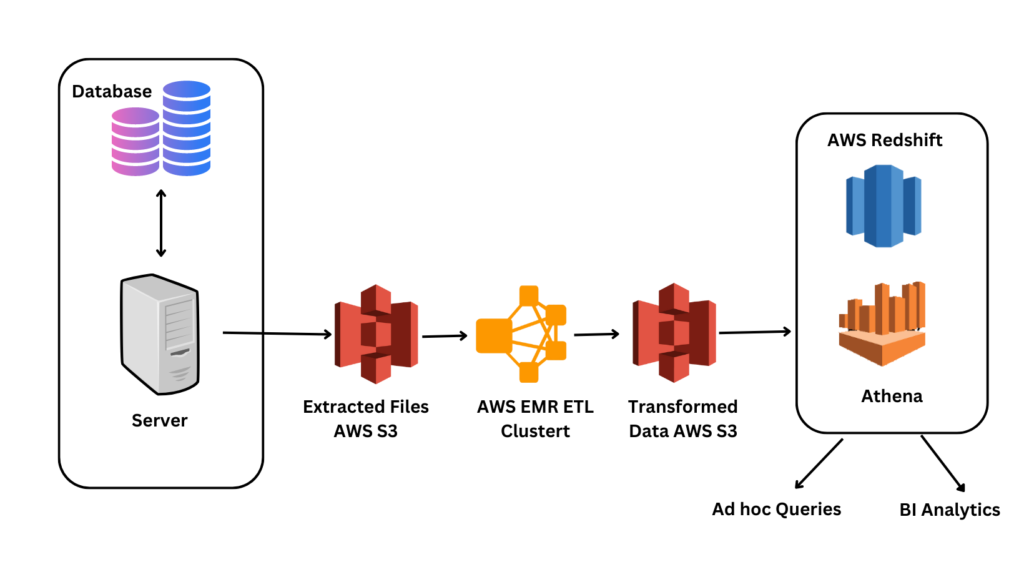 In AWS EMR, we can also transform and move huge volumes of data between Amazon S3 and Amazon DynamoDB, among other AWS databases and data repositories.
In AWS EMR, we can also transform and move huge volumes of data between Amazon S3 and Amazon DynamoDB, among other AWS databases and data repositories.
To construct and launch Jupyter Notebook and JupyterLab interfaces within the Amazon EMR console, use Amazon EMR Notebooks and clusters running Apache Spark. Users can run queries and code in a “serverless” EMR notebook. An EMR notebook’s contents, including the equations, queries, models, code, and narrative text included within notebook cells, run in a client, unlike a typical notebook. On the EMR cluster, a kernel is used to carry out the commands. For longevity and flexible reuse, notebook contents are also saved to Amazon S3 separately from cluster data.
3. AWS Lamda
AWS Lambda is a serverless compute service that runs code for all sorts of applications or backend operations without the necessity to provision or manages them regardless of the utility. Lambda executes code on a high-availability compute infrastructure while handling all compute resource management tasks, such as server and operating system management, capacity provisioning and automatic scaling, and logging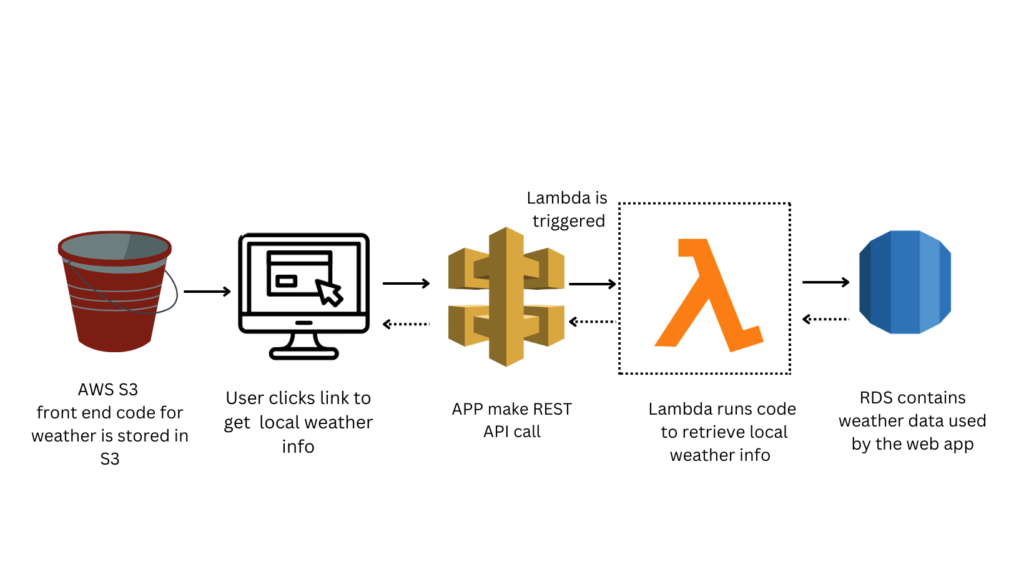 Moreover, it helps majorly in data pipelines for the automation of data quality and control. The simplicity in architecture and easier implementation of code make tasks effortless when using cloud storage like S3. For instance, triggering the lambda function on files hitting the S3 bucket in order to validate the header and rows or if something is incorrect, move the file for deletion and report the error.
Moreover, it helps majorly in data pipelines for the automation of data quality and control. The simplicity in architecture and easier implementation of code make tasks effortless when using cloud storage like S3. For instance, triggering the lambda function on files hitting the S3 bucket in order to validate the header and rows or if something is incorrect, move the file for deletion and report the error.
4. AWS Redshift
Amazon Redshift is a data warehouse in AWS that supports connection with various types of applications, including business intelligence (BI), reporting and data analytics tools. AWS Redshift uses columnar storage model for database tables to optimize analytical query performance as it’s crucial, especially for business intelligence such as Quicksight which deals with thousands and millions of users.
Cluster
A cluster is the primary piece of infrastructure for Amazon Redshift data warehouse. One or more compute nodes make up a cluster. The code is executed by the compute nodes.
An additional leader node controls the compute nodes if a cluster has two or more compute nodes provisioned. The leader node manages connectivity with other programs, such as query editors and business intelligence tools. Only the leader node is directly communicated with by your client application. The compute nodes are accessible to applications running outside of them.
Database
Amazon Redshift characteristics are similar to the relational database management system (RDBMS) and is compatible with other RDBMS applications. It offers the same features as a standard RDBMS, such as online transaction processing (OLTP) capabilities including data insertion and deletion.
5. AWS Athena
Amazon Athena is an interactive query service that allows users to run custom SQL queries over the data available in Amazon S3. Because Athena is serverless, you only pay for the queries you perform and there is no infrastructure to maintain.
Utilizing Athena is simple. Simply specify the schema, point to your data in Amazon S3, and begin basic SQL queries. Most results arrive in a matter of seconds. Complex ETL tasks are not necessary with Athena to prepare your data for analysis. This makes it simple for anyone with SQL knowledge to analyse big datasets rapidly. Since SQL is a key skill for data engineers, working knowledge of Athena is a major advantage.
Some companies may ask for other skills too, however, these are the most common skills required to become an AWS data engineer. Hope this helps in your job findings. Good Luck.
Learning is what makes me excited. I have a handful of experience as a data and BI analyst with broad skills across various tools. I am also a person who take up challenges and who work for it untill it get resolved. I have learnt to be spontaneous and precision in problem solving because of the experience over the years.